LLM Provider Benchmark — "Build Tic-Tac-Toe"
AIFactory is provider-agnostic: the same build task runs on Claude, Gemini, Codex, GitHub Copilot, or a local Ollama model, selected per task by the model string. This page runs the identical task through every provider and reports the real outcome — time, result, and independently-verified tests — including the runs that failed first and what we fixed to make them pass.
The task (identical for every provider)
A small but non-trivial, uniformly testable feature added to the same FastAPI demo repo:
A
tictactoemodule (3×3 board,move(), win/draw detection, invalid-move rejection), exposed via aPOST /tictactoe/moveendpoint, plus a pytest suite covering a win, a draw, and a rejected move.
Python + pytest was chosen deliberately: "result = working" is objectively verifiable by running the tests, and the bar is identical for every provider. Each provider got the same description, ran in its own isolated git worktree, and stopped at the Human Review gate.
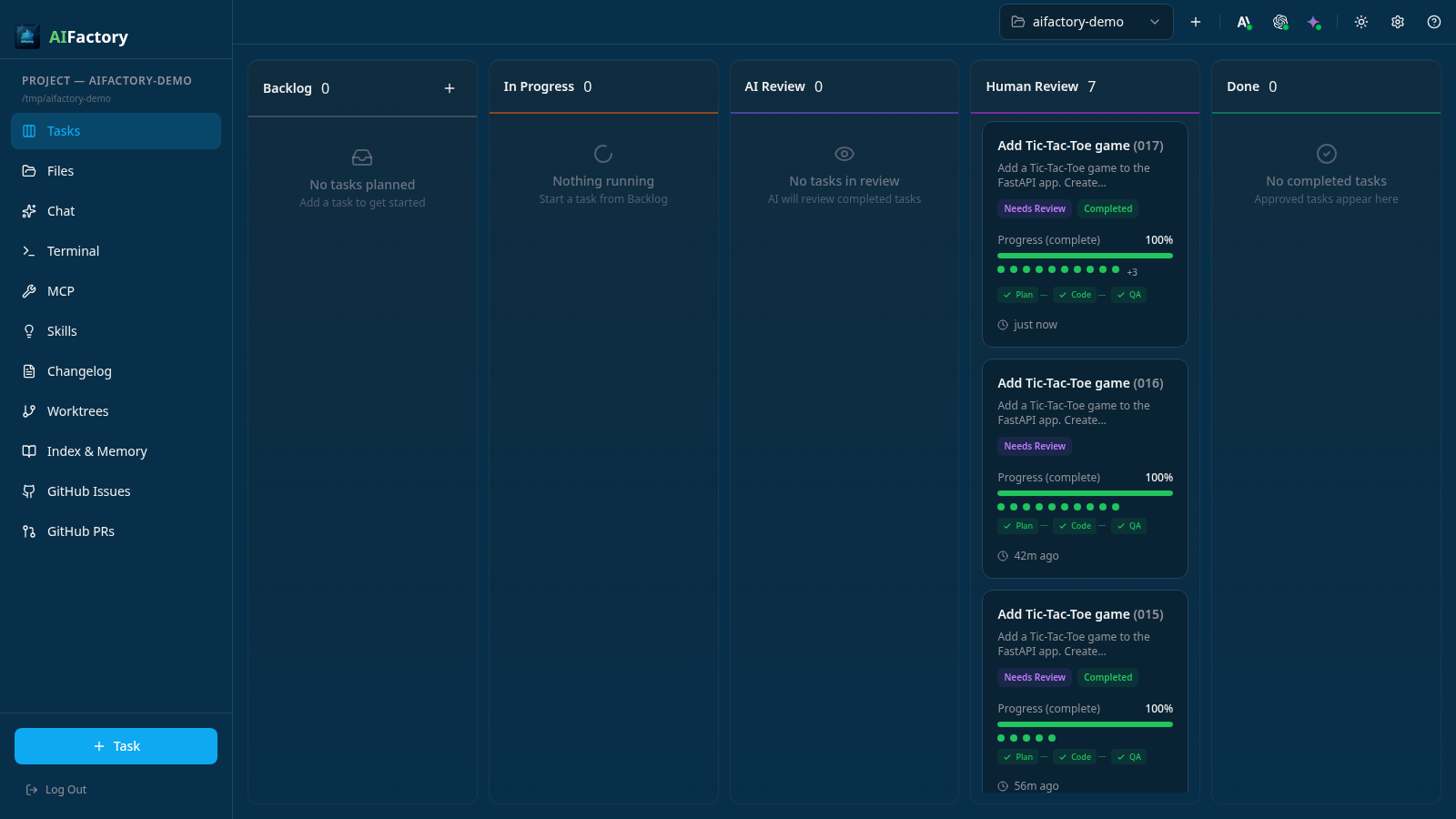
The portal board after the runs — each card at 100% with Plan · Code · QA green.
Results
Every managed provider produced a working, independently-tested feature from the same task.
| Provider | Model | Time | Subtasks | Code | Tests (independent pytest) |
|---|---|---|---|---|---|
| Codex | gpt-5.3-codex | 4m 56s | 5 / 5 | 128 lines | 7 / 7 pass |
| Claude | claude-sonnet-4-6 | 9m 29s | 3 / 3 | 254 lines | 9 / 9 pass |
| Gemini | gemini-3.1-pro-preview | 19m 37s | 13 / 13 | 291 lines | 16 / 16 pass (incl. async API tests) |
| Copilot | copilot:claude-sonnet-4.5 | ~25m¹ | 10 / 10 | 144 lines | 4 / 4 pass |
| Ollama (local) | qwen2.5-coder:14b | 2m 32s² | 1 / 10 | partial | — (feature incomplete) |
Times are wall-clock from task-create to the Human Review gate. Tests were re-run independently on each provider's branch in a clean virtualenv — these are not the agent's self-reported numbers.
¹ Copilot completed all 10 subtasks and its tests pass, but it's the slowest: the GitHub Copilot CLI adds a per-tool routing/approval layer, and the run reached the gate right as the benchmark's 25-minute poll window closed.
² Ollama's number is after a provider fix (see below): the local qwen2.5-coder:14b
went from writing 0 files to writing real code (a partial TicTacToe module), but a
14B model isn't large enough to finish the whole multi-file feature — it stopped after the
first subtask. Completing the full task needs a larger local model (≈27B-class); that's a
hardware question, not an AIFactory one.
Cost, honestly
AIFactory does not yet persist per-build token usage, so exact per-build cost isn't measured here. The shape is: Ollama is $0 (your own hardware); Claude / Gemini / Codex meter at public per-token rates and land in the order of a few cents for a task this size; Copilot bills against your GitHub Copilot subscription in premium requests rather than tokens. Persisting exact per-build usage is a tracked follow-up.
Best tool for the job
- Fastest working build → Codex (
gpt-5.3-codex). 4m 56s end-to-end with passing tests — roughly twice as fast as the rest. - Cleanest first pass → Claude (
claude-sonnet-4-6). Followed the spec exactly (synchronousTestClient), 9/9 on the first run, no fixes needed. - Most thorough coverage → Gemini (
gemini-3.1-pro-preview). Wrote the largest suite (16 tests, including idiomatic asynchttpxAPI tests) once the repo was configured for async tests. - Convenient via an existing subscription → Copilot (
copilot:claude-sonnet-4.5). Works with your GitHub Copilot plan and no extra API key; slowest, but correct. - Cheapest → Ollama. $0 on local hardware. After the provider fix below, a small local
model (
qwen2.5-coder:14b) now produces real code instead of nothing — but finishing a full multi-file feature still needs a larger local model (≈27B-class). "Free" works; "free and complete" depends on the GPU you can spare.
What the failures taught us — and what we fixed
The benchmark surfaced four real, fixable issues. That's the point of running it.
- Codex produced nothing on the first run (0 files). Root cause: the agentic Codex
provider drained only stdout while the Codex MCP server filled its stderr pipe buffer
(~64 KB) and blocked. Fixed by draining stderr concurrently and resolving the
codexshell alias tocodex-cli(PR #243). The after-fix run is the fastest in the table. - Gemini's tests failed even though its code was correct. Gemini wrote idiomatic async
FastAPI tests (
@pytest.mark.asyncio+httpx.AsyncClient), but the repo had nopytest-asyncioconfigured — pytest reported "async def functions are not natively supported." Fixed by addingpytest-asyncioandasyncio_mode = "auto"so the repo accepts both synchronousTestClientand async test styles. Result on a fresh re-run: 16 / 16 pass. - Copilot wasn't supported at all. AIFactory had no Copilot provider, so we added one
(PR #244): a
CopilotAgenticProviderthat drivescopilot -p … --allow-all-tools, selectable with acopilot:<backend>model string. Copilot is a router overclaude-sonnet-4.5/claude-sonnet-4/gpt-5. - Ollama wrote nothing (0 files). Root cause: small local models (qwen, llama) often emit
a tool call as a
```json {"name","arguments"}```text block instead of the nativetool_callsfield, so the agent'sWritenever executed; they also tend to loop onReadand never reach the final write. Fixed by parsing text-emitted tool calls and adding a read-loop convergence nudge — ported from the sister TFactory project, which had already solved it (PR #247). With the fix the 14B now produces real code; finishing the full feature is then just a question of local model size.
Reproduce it
# One provider at a time (runs the identical Tic-Tac-Toe task):
DEMO_PROVIDER=claude DEMO_MODEL=sonnet node scripts/benchmark-provider.mjs
DEMO_PROVIDER=codex DEMO_MODEL=gpt-5.3-codex node scripts/benchmark-provider.mjs
DEMO_PROVIDER=gemini DEMO_MODEL=gemini-3.1-pro-preview node scripts/benchmark-provider.mjs
DEMO_PROVIDER=copilot DEMO_MODEL=copilot:claude-sonnet-4.5 node scripts/benchmark-provider.mjs
DEMO_PROVIDER=ollama DEMO_MODEL=ollama:qwen2.5-coder:14b node scripts/benchmark-provider.mjs
Each run writes /tmp/aifactory-bench/<provider>.json with the time, subtask counts, and
the produced diff. Re-run pytest on each aifactory/<spec> branch to verify the tests
yourself.